
SnowflakeのINCLUDE_METADATAオプションを用いてファイル名などのメタデータを取得しつつcsvファイルをロードしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
SnowflakeのFILE_FORMATのINCLUDE_METADATAオプションを用いてファイル名などのメタデータを取得しつつcsvファイルをロードしてみたので、その内容を本記事でまとめてみます。
INCLUDE_METADATAオプションについて
まず、INCLUDE_METADATAオプションですが、FILE_FORMATに関するオプションとなります。
この機能の良さをわかりやすく説明しているのが下記のブログとなります。
以下のコードはこのブログからの引用ですが、INCLUDE_METADATAがリリースされる前は、ファイル名などのメタデータを取得するにはCOPY INTO文の中でSELECT文を書く必要がありました。
- Before(
INCLUDE_METADATAリリース前)
-- Manually determine the column name, types, ordering
-- Hard code the copy definition for a single schema
COPY INTO PARQUET_LOAD
FROM (
SELECT
$1:YEAR::number(4,0),
$1:NUMBER::float,
$1:TYPE::string,
$1:COMMENT::string,
$1:EVENT::string,
METADATA$FILENAME,
METADATA$FILE_LAST_MODIFIED,
METADATA$START_SCAN_TIME
FROM @XIN_S3_STAGE/schema_evolution/ )
FILE_FORMAT = 'PARQUET_SCHEMA_DETECTION'
ON_ERROR = CONTINUE
FILES = ('small.parquet');
しかし、INCLUDE_METADATAのリリース後は、下記のようにINCLUDE_METADATAというオプションをつけるだけで指定したメタデータをロードすることができます。わざわざSELECT文を書かなくて済むのが良いですね!
- After(
INCLUDE_METADATAのリリース後)
-- Automatically load with MATCH_BY_COLUMN_NAME and INCLUDE_METADATA
COPY INTO PARQUET_LOAD
FROM @XIN_S3_STAGE/schema_evolution/
FILE_FORMAT = 'PARQUET_SCHEMA_DETECTION'
ON_ERROR = CONTINUE
MATCH_BY_COLUMN_NAME = CASE_SENSITIVE
INCLUDE_METADATA = (
FILENAME=METADATA$FILENAME,
FILE_LAST_MODIFIED=METADATA$FILE_LAST_MODIFIED,
FILE_SCAN_TIME=METADATA$START_SCAN_TIME)
FILES = ('small.parquet');
csvファイルのロードでINCLUDE_METADATAオプションを使ってみた
上述の記事ではparquetファイルをロードしていましたが、今回はcsvファイルのロードでINCLUDE_METADATAオプションを試してみます。(csvファイルの場合は、FILE_FORMATの設定でERROR_ON_COLUMN_COUNT_MISMATCH = FALSEが必要なためです。)
ロード対象のデータ
下記のClaude 3.5に作成してもらったサンプルデータを使用します。
order_id,customer_name,product_name,quantity,unit_price,total_amount,order_date
1001,Taro Sato,Smartphone,1,80000,80000,2023-05-01
1002,Hanako Suzuki,Laptop,1,120000,120000,2023-05-02
1003,Jiro Tanaka,Wireless Earphones,2,15000,30000,2023-05-02
1004,Misaki Yamamoto,Tablet,1,50000,50000,2023-05-03
1005,Kenta Nakamura,Smartwatch,1,30000,30000,2023-05-03
1006,Ai Kobayashi,Digital Camera,1,70000,70000,2023-05-04
1007,Yuko Kato,Printer,1,25000,25000,2023-05-04
1008,Yuta Ito,External HDD,2,8000,16000,2023-05-05
1009,Mari Watanabe,Gaming Mouse,1,12000,12000,2023-05-05
1010,Kazuya Takahashi,Keyboard,1,9000,9000,2023-05-06
1011,Sakura Matsumoto,Monitor,1,35000,35000,2023-05-06
1012,Takuya Kimura,Speakers,2,20000,40000,2023-05-07
1013,Akiko Hayashi,Router,1,10000,10000,2023-05-07
1014,Ken Saito,USB Flash Drive,3,2000,6000,2023-05-08
1015,Yuko Yamada,Mouse Pad,2,1500,3000,2023-05-08
1016,Takashi Okada,Headset,1,18000,18000,2023-05-09
1017,Mayumi Goto,Webcam,1,8000,8000,2023-05-09
1018,Daisuke Nakajima,Gaming Chair,1,40000,40000,2023-05-10
1019,Keiko Maeda,Charger,2,3000,6000,2023-05-10
1020,Shota Fujita,Laptop Bag,1,5000,5000,2023-05-10
スキーマ・ステージ・テーブルの定義
以下のクエリを実行して、スキーマ・ステージ・テーブルの定義を行います。ステージの作成後にcsvファイルのアップロードも行います。
create schema metadata_test;
use schema metadata_test;
create stage csv_stage;
create or replace table ec_site_data (
order_id int,
customer_name varchar(100),
product_name varchar(100),
quantity int,
unit_price int,
total_amount int,
order_date date,
filename varchar(255),
file_row_number int,
file_content_key varchar(255),
file_last_modified timestamp_ntz,
start_scan_time timestamp_ntz
);
方法その1:FILE_FORMATの作成時にERROR_ON_COLUMN_COUNT_MISMATCH=FALSEを指定する
まず1つ目の方法として、FILE_FORMATの作成時にERROR_ON_COLUMN_COUNT_MISMATCH = FALSEを指定する方法でロードしてみます。
注意点として、以下2点が挙げられます。
- FILE_FORMATの定義時に
PARSE_HEADER = TRUEが必要 - COPY INTOの定義時に
MATCH_BY_COLUMN_NAMEの指定が必要
create or replace file format csv_file_format
type = 'csv'
parse_header = true
error_on_column_count_mismatch = false
field_delimiter = ','
;
copy into ec_site_data
from @csv_stage/
file_format = csv_file_format
match_by_column_name = case_insensitive
include_metadata = (
filename = metadata$filename,
file_row_number = metadata$file_row_number,
file_content_key = metadata$file_content_key,
file_last_modified = metadata$file_last_modified,
start_scan_time = metadata$start_scan_time)
files = ('ec_sample.csv')
;
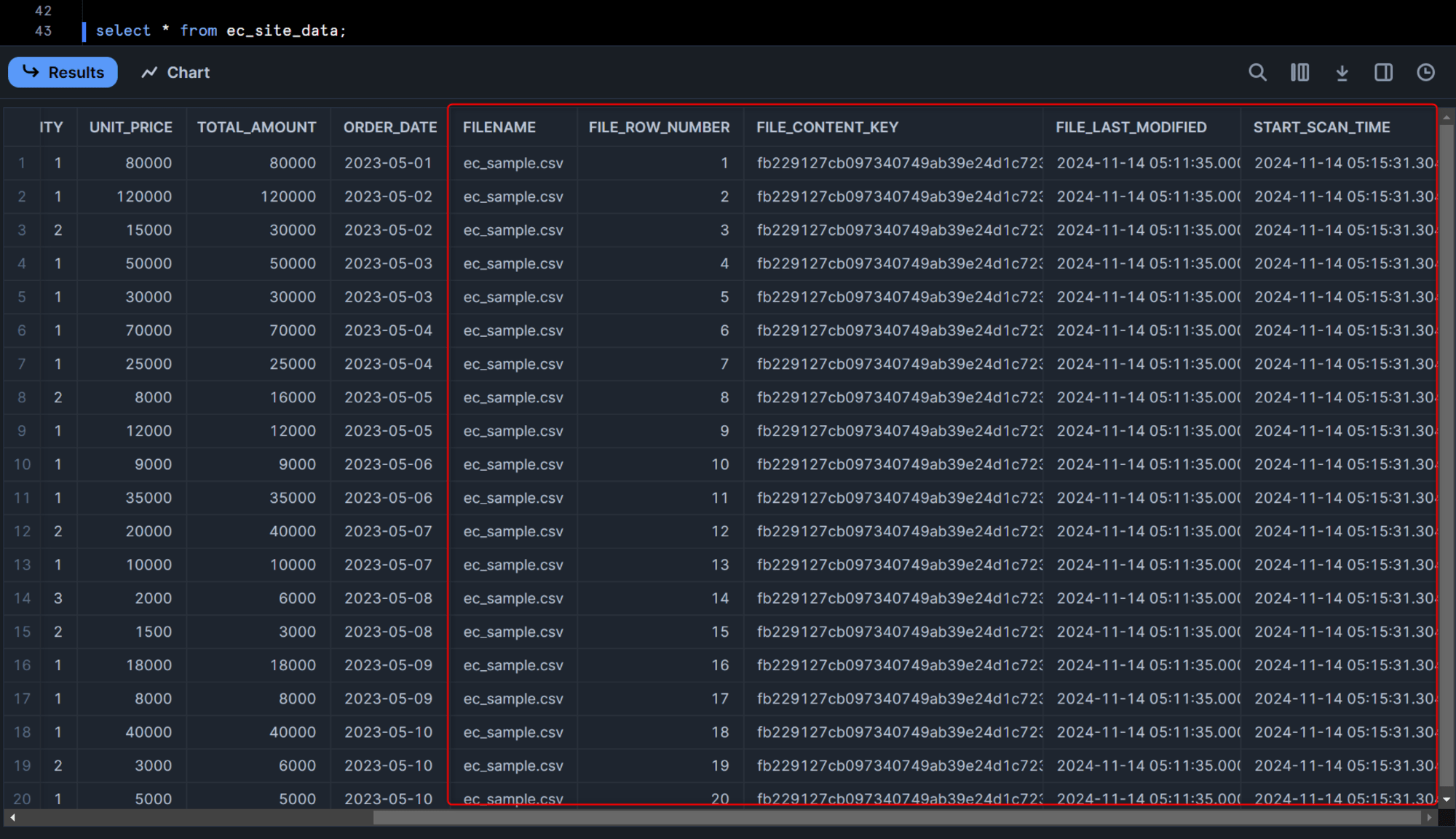
この後でロードしたデータをクエリしてみると、下図のように各種ファイルに関するメタデータも併せて記録されているのがわかると思います。
方法その2:COPY INTOコマンドの定義時にERROR_ON_COLUMN_COUNT_MISMATCH=FALSEを指定する
もう一つおまけに、COPY INTOコマンドの定義時にERROR_ON_COLUMN_COUNT_MISMATCH = FALSEを指定する方法でもロードしてみます。
すでにCSV用のファイルフォーマットはあって、ERROR_ON_COLUMN_COUNT_MISMATCH = FALSEは一部のテーブルでのみ使いたい、という場合はこちらの方法が合っていると思います。
注意点として、以下3点が挙げられます。
- FILE_FORMATの定義時に
PARSE_HEADER = TRUEが必要 - COPY INTOの定義時に
MATCH_BY_COLUMN_NAMEの指定が必要 - COPY INTOの定義時に、
FILE_FORMATパラメータでFORMAT_NAMEの指定とERROR_ON_COLUMN_COUNT_MISMATCH = FALSEの指定が必要
create or replace file format csv_file_format
type = 'csv'
parse_header = true
field_delimiter = ','
;
copy into ec_site_data
from @csv_stage/
file_format = (
format_name = csv_file_format
error_on_column_count_mismatch = false
)
match_by_column_name = case_insensitive
include_metadata = (
filename = metadata$filename,
file_row_number = metadata$file_row_number,
file_content_key = metadata$file_content_key,
file_last_modified = metadata$file_last_modified,
start_scan_time = metadata$start_scan_time)
files = ('ec_sample.csv')
;
最後に
SnowflakeのFILE_FORMATのINCLUDE_METADATAオプションを用いてファイル名などのメタデータを取得しつつcsvファイルをロードしてみたので、その内容をまとめてみました。
ファイルのメタデータをロードしたい場合にはとても役立つオプションだと思います!ぜひご利用ください。







